Taking a Look at Competitive Programming
Introduction
Competitive programming is a lucrative business if you have the chops for it. It has however been subject to little analysis AFAIK. This has partially been because of the unavailability of consolidated data set to facilitate this. To resolve that I scraped together data from the Codechef website amounting to a little over 1 million programs submitted to the site. You can get the dataset on Kaggle (link to data).
The purpose of this work is to get started with the OpenAI special project which states
An Exploratory Data Analysis has been done by Swaraj Khadanga. You can see it at Simple EDA.
The purpose of this work is to get started with the OpenAI special project which states
To solve a problem, the first step is always to understand the problem and know it's quirks. This blog post is possibly the first of many exploring this dataset with the ultimate aim of being able to generate a solution program given the statement of the problem.Build an agent to win online programming competitions. A program that can write other programs would be, for obvious reasons, very powerful.
An Exploratory Data Analysis has been done by Swaraj Khadanga. You can see it at Simple EDA.
A brief description of the data
The dataset presents a table with columns as variables and rows as observations, making it tidy in the process. The columns we are interested in are:
- QCode : The Question Code, denoting a unique question
- Solution : The program written by the user
- Status : Was it a correct attempt or not?
- Language : The language that the code was written in.
Program Visualization
This visualization makes some assumptions, namely:
- We consider only those programs which were written in C
- We reduce each program to another string, keeping only keywords and special characters. The idea is to try and get an approximate representation of the Abstract Syntax Tree by obtaining an infix representation of the code.
- With these program representations as representations of the programs, we calculate the Levenshtein distance between each pair of representations.
- Using the above data we have a complete graph with each vertex representing a program and each edge being the Levenshtein distance between two programs.
- Now, we place each vertex in a 2D plane at coordinates such that the difference between the distances between points on the plane and the Levenshtein distance between two points is minimal. This is similar to what has been done by Ben in his post on numerical optimization in the Last cities example.
We plot the points at the calculated coordinates and color them by the problem they were trying to solve. By doing this we arrive on a graph which is shown below.
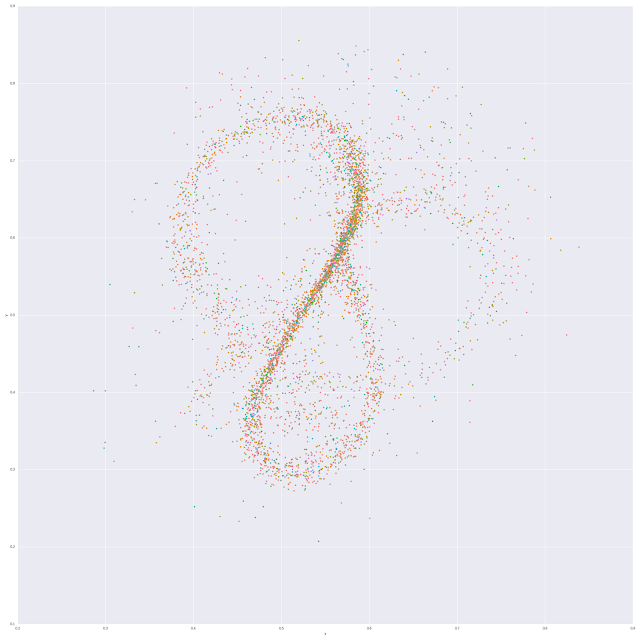

All I can say at this point is that it's interesting. The X and Y represent nothing of significance. What is significant is the relative distances between the points. Most programs are of a similar structure with very few actually differing a lot from each other.
There will be more on this in later posts. The plot was created using this gist.
· · ·